[2/7/26] I'm back with some updates! Unfortunately, I haven't been able to code more of the compiler, but I spent some time learning more theory and cool technologies that I wanted to share.
[1/22/26] It's been a few weeks of work (and travelling), but I'm here to report my current progress. The past few weeks involved a lot of reading and learning on these topics:
PyTorch 2 (TorchDynamo/TorchInductor): this was a useful starting point as the paper discusses the implementation decisions behind TorchDynamo and its Graph Capture mechanism. This essentially helped me narrow down my design to use PyTorch's torch.fx toolkit.
A major development includes my Python frontend & Rust setup. This project is actually my 2nd time ever using Rust: for setup purposes, I familiarized myself with Cargo (Rust's package management system), and I'm getting the hang of the memory lifetime model that Rust provides. I also played around with Rust bindings for PyTorch (provided by PyO3) and
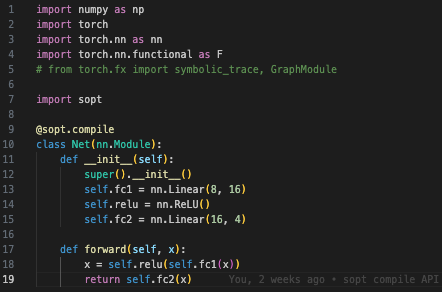
Rust bindings for MLIR (via Melior). What's next? I have to get my hands dirty with MLIR. I have been using the Toy example to learn implementation fundamentals for an MLIR-based compiler. sopt API usage Above, I have a very simple 2-layer network defined using PyTorch. Similar to PyTorch, I utilize a compile() decorator under my own sopt library. Taking a step back from the technical side, I also wanted
to share how fascinating I found this step; I essentially built my own importable Python library that funnels into the binary for my Rust-based compiler! Many libraries that I use
on a daily basis follow some form of what I've just implemented here, which was eye-opening to me.
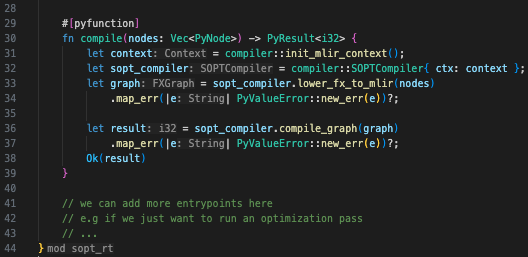
Anyway, during execution, sopt.compile() converts the torch.fx format into a list of related JSON objects that can easily be received by the Rust backend. I set up a class, PyNode, that encapsulates the important data fields from FXNodes. sopt compiler receiver endpoint for sopt.compile() From this point, I am working on setting up my first Dialect/IR on the MLIR skeleton. I call it the "soptfx" dialect. The idea is to lower the PyNodes to operations in MLIR in order to make the data graph; since FX nodes come in 3 main flavors
(placeholders, callfunctions, and outputs), I handle this lowering separately for each case. My goal here is to output an accurate .mlir file in order to gauge the correctness of my current logic.
[1/4/26] So, I've been working on this project for the past few weeks. Up until yesterday, I spent most of my time reading up on basic theory behind
ML/DL compilers. I plan to add much more to this blog to help me reinforce whatever I learn and to log my journey into this field (incase it inspires anyone).
I'll get started with some preliminaries: my related background up to this point involves GPU programming (CUDA), systems programming, ML systems, and a bit of compiler construction (LLVM).
All of these were picked up through courses at my school, UIUC.
Over the past few weeks, I read up on a few more technologies:
MLIR
TVM
Triton
TensorRT
nvFuser
Now, I somewhat understand where these technologies fit into a compiler stack.
MLIR serves as compiler infrastructure, the "skeleton" of the compiler we build;
TVM is a fullstack compiler that emphasizes loop-level/tiling optimizations and code generation for heterogenous devices;
Triton is a language/IR/JIT compiler (used by PyTorch 2.0) that helps write extensible GPU kernels;
TensorRT is an inference engine that optimizes models for NVIDIA GPUs;
and nvFuser is a "Fusion Code Generator" that generates code optimized for NVIDIA GPUs.
I will revisit these definitions the more I explore :)
Now, I have finalized my design that I want to use for this project. I call it "soptRT" (still need to think of a better name).
I've broken this project down into 2 phases:
Phase I: To better learn ML optimizations at a low-level, I want to introduce my own compile() trigger in PyTorch that calls a Rust-based compiler that is built on MLIR. This compiler will trigger optimization passes (Fusion, Quantization, Memory Mapping, etc) and funnel into an existing backend (Triton/TVM).
Phase II: Next, I want to design my own kernel generator. After reading a little, I realized that code generation is a very interesting problem that currently uses several solutions to implement. TVM uses a paradigm called ML for ML, while engineers handcraft kernels for NVIDIA's cuDNN. Details for this part are TBD and will require me to read a bit more.
Great! Now that the plan is out of the way, I will update this page over time with challenges I run into. For now, I am working on creating the "bridge" from my own PyTorch compile() and my Rust backend with MLIR.
Stay tuned!
Cool links: I'd also like to highlight some cool links I found throughout this project. There are a lot of cool startups and innovations in this field of ML compilers that I want to further explore:
Tile IR: NVIDIA released this somewhat recently. This is a "low-level tile virtual machine" allowing a developer to work in terms of tiles.
Modular: really cool company led by Chris Lattner who I've been following for a while. The language seems very well-designed and I am curious to see how its compiler works.